Extraction Evaluation
Measuring structured information extraction accuracy at the field level using precision, recall, F1, and semantic similarity.
The Problem
When converting unstructured organizational inputs — voice recordings, field notes, inspection reports — into structured records, each extracted field must be reliable enough to feed downstream reporting, compliance systems, or databases. A single misclassified near-miss flag or a missing consequence description can invalidate a safety report.
Key challenges include:
- Field accuracy — each extracted field must match the intended value, not a plausible-sounding alternative
- Empty field handling — correctly recognizing when information is absent is as important as capturing what is present
- Semantic variation — descriptive fields can be phrased many ways; wording-exact matching penalizes correct paraphrases
- Ambiguous spoken input — boundaries between field values (e.g. near-miss vs. direct incident) are often unclear in natural speech
- Domain terminology — industry-specific vocabulary and Finnish morphology can lead to systematic extraction errors
For example, extracting an incident report from a spoken safety observation:
- Report type: Safety observation
- Observer name: Matti Möttönen
- Date: 26.8.2025
- What happened: A subcontractor's water cart was parked exemplarily, marked with cones and wheel chocks
- Near-miss: No
How We Evaluate
Extraction quality is measured by comparing AI-extracted JSON fields against human-annotated ground-truth JSON files. Each field is evaluated individually using one of two comparison strategies depending on its type.
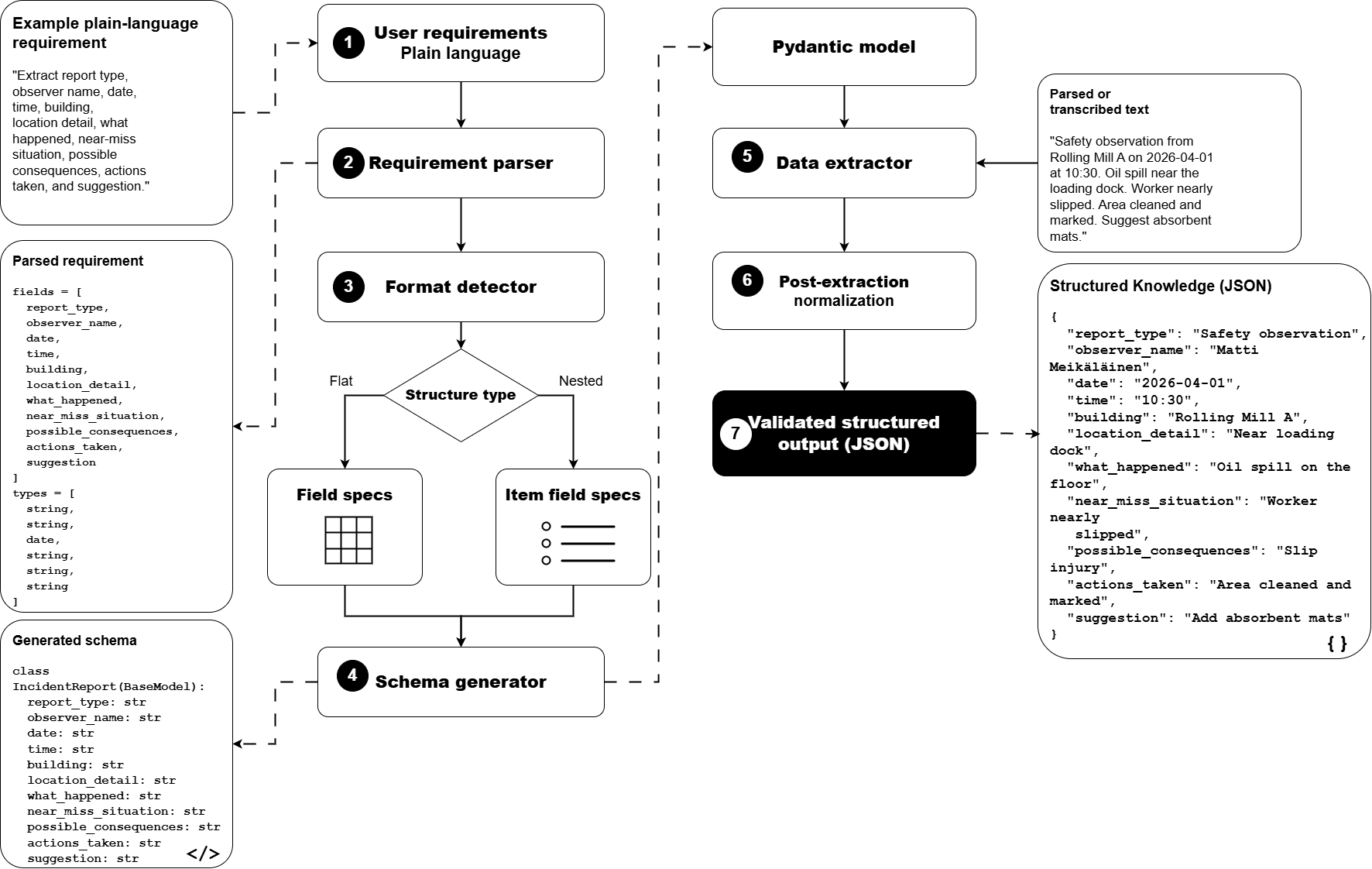
The figure below shows the internal steps of the GAIK extraction component: plain-language requirements are parsed into field specifications, a Pydantic schema is generated, and the extractor applies that schema to parsed or transcribed text to produce a validated structured JSON output.
Exact Fields
Exact fields require precise agreement — category values, names, dates, and Yes/No flags. They are compared using normalized string matching:
- Text is lowercased, whitespace collapsed, and punctuation stripped
- Dates are normalized across Finnish (
26.8.2025) and ISO (2025-08-26) formats before comparison
Exact fields in the incident-reporting schema: report type, observer name, organization, summer-employee flag, date, time, near-miss flag.
Semantic Fields
Descriptive fields may be correctly extracted even when expressed with different wording. These are compared using OpenAI text-embedding-3-large embeddings and cosine similarity. A field is accepted as a match when similarity ≥ 0.50.
Semantic fields in the incident-reporting schema: building/area, location detail, what happened, possible consequences, actions taken, suggestion.
Evaluation Metrics
Five metrics are reported for each evaluation run:
| Metric | Formula | What it measures |
|---|---|---|
| Precision | TP / (TP + FP) | How often system-filled fields were correct |
| Recall | TP / (TP + FN) | How often expected fields were captured |
| F1 Score | 2·P·R / (P+R) | Balanced summary of precision and recall |
| Exact Match Rate (EMR) | (TP+TN) / all exact fields | Correct handling of structured, unambiguous fields |
| Semantic Match Rate (SMR) | (TP+TN) / all semantic fields | Correct handling of descriptive free-text fields |
A True Negative (TN) is counted when both ground truth and prediction are empty — correctly recognizing absent information. A mismatch where both sides are non-empty counts as both a False Positive and a False Negative, applying strict field-level penalty.
Benchmarking Results
A pilot evaluation was conducted on 15 incident-reporting audio samples provided by a partner company. The figure below shows the evaluated workflow: employees record spoken safety observations on a mobile device; the audio is transcribed, enhanced using a 2-pass LLM method, and passed to the data extractor, which fills in the structured incident report fields for user review before transfer to the reporting system.
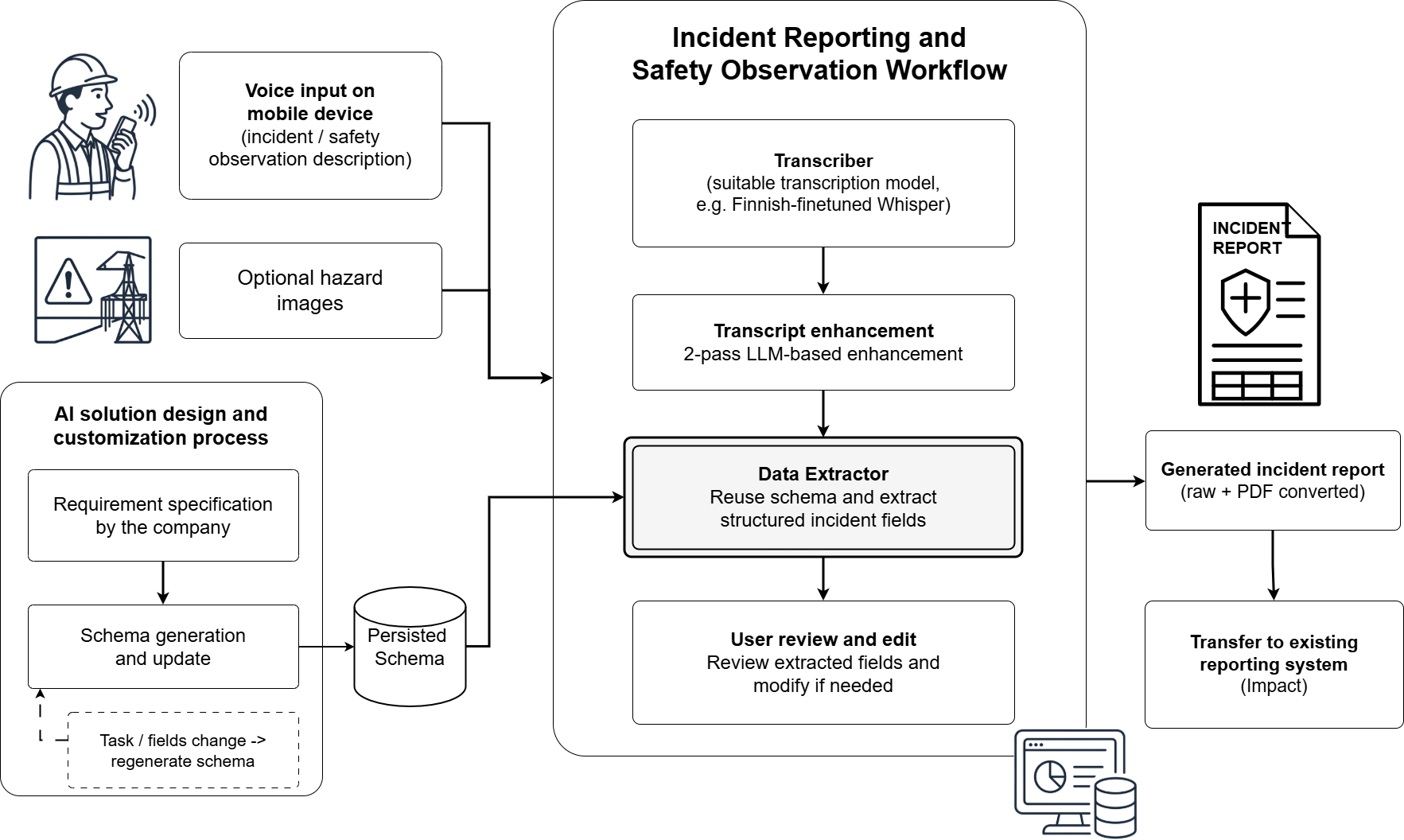
Company representatives manually filled in the ground-truth JSON for each recording. The AI workflow (transcription → 2-pass enhancement → schema-guided extraction) produced the predicted JSON files, which were compared against ground truth using evaluate.py.
Aggregate Results
| Metric | Score |
|---|---|
| Precision | 90.00% |
| Recall | 87.10% |
| F1 Score | 88.52% |
| Exact Match Rate (EMR) | 90.67% |
| Semantic Match Rate (SMR) | 87.78% |
Key Findings
- Structured, unambiguous fields extract most reliably — categorical and Yes/No fields that have a clear, expected value achieve the highest accuracy
- Ambiguous classification boundaries reduce exact field accuracy — fields where the distinction between two valid values depends on interpretation (e.g. near-miss vs. direct incident) are the most error-prone exact fields
- Descriptive fields with implied content have lower recall — when information is present in the audio but not explicitly stated, the extractor tends to leave the field empty rather than infer
- Enhancement improves extraction upstream — transcript quality directly bounds extraction quality; 2-pass LLM enhancement reduces spelling and structural errors before extraction runs
- Semantic threshold calibration matters — the 0.50 threshold was selected through analysis of matched pairs; different use cases may require different thresholds based on acceptable paraphrase tolerance
Error Classification
Transcription Errors
Problem: Errors introduced during speech-to-text conversion propagate directly into the extraction step. If a word is misheard or dropped in the transcript, the extractor works from faulty input and cannot recover the correct value.
Impact: Extraction errors that originate in transcription cannot be fixed by improving the extraction prompt alone — they require better transcription models or post-transcription enhancement.
Proper Noun Errors
Problem: Names of people, organizations, locations, and products are frequently garbled during transcription or misidentified during extraction, as they fall outside standard vocabulary and model training data.
Impact: Observer names, company names, and location identifiers may be recorded incorrectly, requiring manual correction before the report is submitted.
Formatting Inconsistency
Problem: The same information can be formatted differently across extractions — dates written as 26.8.2025 vs. 2025-08-26, names with varying capitalization, or numbers expressed as digits vs. words.
Impact: Inconsistent formatting complicates downstream processing, database storage, and automated comparison against ground truth.
Missing Information
Problem: When the spoken input is ambiguous, fragmented, or uses implied rather than explicit language, the extractor may leave fields empty even when the relevant information is present in the transcript.
Impact: Incomplete records that require manual review and completion before use in reporting or compliance workflows.
Misinterpreted Information
Problem: An imprecise or ambiguous extraction prompt can cause the model to assign a value to the wrong field, use an incorrect category, or conflate two distinct concepts (e.g. consequences vs. actions taken).
Impact: Structurally valid but semantically incorrect records that may pass automated validation while containing wrong data.
Real-World Applications
The same field-level evaluation methodology has been applied across multiple GAIK extraction use cases:
- Incident reporting — Converting spoken workplace safety observations into structured incident report fields. Pilot evaluation (15 samples): Precision 90.00%, Recall 87.10%, F1 88.52%.
- Construction site diary creation — Extracting daily progress, tasks, and observations from field notes or voice recordings into standardized diary entries.
- Safety observation reporting — Structuring safety walk-around observations and positive reinforcement notes into company reporting schemas.
The evaluation schema and evaluate.py script are designed to be reused across these contexts by swapping the ground-truth and prediction data and adjusting field definitions and thresholds.
Quality Considerations
When deploying extraction evaluation in your own context, consider:
Threshold calibration — The 0.50 semantic threshold was selected through manual analysis of matched pairs. For safety-critical or compliance reporting, a stricter threshold (0.60–0.70) may be more appropriate. For general reporting where paraphrase is acceptable, 0.45–0.50 is reasonable.
Field type assignment — Deciding which fields are "exact" vs. "semantic" significantly affects scores. Fields with enumerated or structured values (dates, categories, Yes/No) should always be exact; open-ended descriptions should be semantic.
Empty field convention — Consistent handling of missing values between ground truth and predictions is critical. If the ground truth uses empty strings and predictions use null, comparison logic must normalize both to the same representation.
Dataset size — The pilot evaluation used 15 samples. More samples across diverse speakers, incident types, and audio conditions are needed for stable benchmarks.
Upstream quality — Extraction quality is bounded by transcription quality. Poor transcription produces poor inputs, regardless of extractor capability. Evaluate the full pipeline, not just the extraction step in isolation.
Getting Started
To run extraction evaluation in your own context:
- Define the extraction schema fields and classify each as exact or semantic
- Collect a representative set of input recordings and produce transcripts
- Have domain experts fill in ground-truth JSON files for each input
- Run the extraction workflow (transcription → enhancement → extraction) to produce predicted JSON files
- Place matched ground-truth and prediction files in
data/ground truth/anddata/predictions/, then runpython evaluate.py - Review
IE_report_70%.txtand adjust the semantic threshold or extraction prompt based on field-level results
For technical implementation details, the evaluation script, and example data structures, visit the GAIK GitHub repository.