Extraction Evaluation
Measuring structured information extraction accuracy
The Problem
When extracting structured information from text (like filling out form fields from a voice recording or document), accuracy is essential for business processes. Whether it's incident reports, construction diaries, or customer information, extracted data must be reliable and complete.
Key challenges include:
- Field accuracy - Each extracted field must match the intended information
- Missing information - Correctly identifying when information is not available
- Semantic understanding - Capturing meaning, not just exact words
- Consistency - Maintaining uniform formatting across extractions
- Domain terminology - Understanding industry-specific language and context
For example, extracting incident report fields from a voice recording:
- Report type: Safety observation
- Location: Building A, Assembly line
- Date/Time: 15.03.2024 14:30
- Severity: Yes (near miss)
- Description: Equipment malfunction, safety protocol followed
How We Evaluate
Extraction quality is measured by comparing AI-extracted fields against verified reference data (ground truth). Each field is evaluated for accuracy using similarity scoring.
Field-Level Assessment
Fields are grouped into two categories based on required accuracy:
Exact Fields - Require very high precision (95% similarity threshold)
- Report types and categories
- Dates and times
- Yes/No answers
- Predefined options (dropdown selections)
Semantic Fields - Focus on meaning over exact wording (80% similarity threshold)
- Text descriptions and narratives
- Location details
- Action descriptions
- Explanatory notes
Similarity Scoring
Each extracted field is compared to its reference value using semantic similarity:
- PASS - Field value is sufficiently similar to reference (above threshold)
- ERROR - Field value differs significantly from reference (below threshold)
The evaluation measures:
- Overall matching rate - Percentage of all fields correctly extracted
- True positives - Correctly extracted non-empty fields
- False positives - Incorrectly extracted or hallucinated content
- False negatives - Missing fields that should have been extracted
- Field-wise accuracy - Individual field performance for targeted improvements
Benchmarking Results
We evaluated multiple AI models for extracting structured incident report fields from Finnish transcripts.
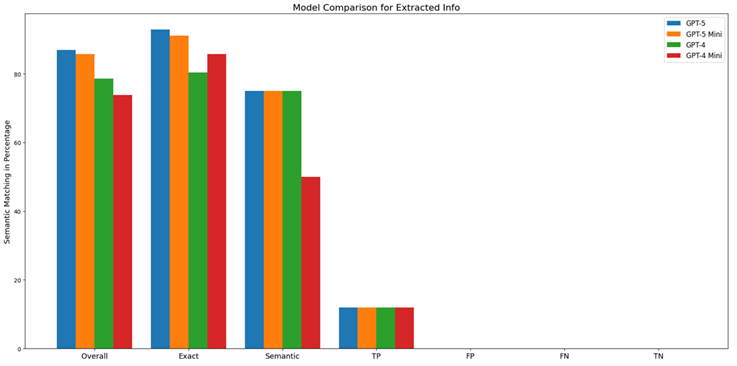
Model Performance Comparison
Different AI models show varying performance for structured extraction tasks:
- Top performers demonstrate strong semantic understanding and consistent field extraction
- Mid-range models provide acceptable accuracy with faster processing
- Trade-offs exist between extraction accuracy, processing speed, and cost
Key Findings
- Model selection matters - Different models excel at different field types
- Context understanding - Better models correctly interpret domain terminology
- Error patterns - Some models struggle with specific field categories
- Consistency varies - Extraction reliability differs across content types
Common Extraction Errors
Field Confusion
Problem: Information extracted into wrong fields
- Date information appearing in location field
- Severity mixed with event description
Impact: Misorganized data requires manual correction
Missing Information Handling
Problem: Incorrectly marking fields as present or empty
- Extracting placeholder text for unavailable information
- Leaving populated fields blank
Impact: Incomplete reports or false data
Semantic Misunderstanding
Problem: Misinterpreting meaning despite similar words
- "Near miss" vs. "Actual incident"
- "Completed" vs. "Ongoing"
Impact: Critical information misrepresented
Formatting Inconsistency
Problem: Same information formatted differently across extractions
- Date formats: "15.03.2024" vs. "March 15, 2024"
- Time formats: "14:30" vs. "2:30 PM"
Impact: Data processing and analysis complications
Real-World Applications
Extraction evaluation supports these GAIK use cases:
- Incident Reporting - Extracting structured safety observations from voice recordings
- Construction Site Diaries - Organizing daily field notes into standardized formats
- Document Processing - Converting unstructured reports into database entries
- Form Filling - Automatically populating forms from dictated or written content
Quality Considerations
When evaluating extraction quality for your specific use case, consider:
Critical vs. Optional Fields - Which fields require perfect accuracy vs. reasonable approximation?
Error Tolerance - What level of extraction error is acceptable before manual review is needed?
Field Dependencies - Do certain fields depend on others being correct?
Domain Specificity - How well does the model understand your industry terminology?
Volume vs. Accuracy - Is high-volume automated processing or perfect extraction more important?
Improving Extraction Quality
Based on evaluation results, quality can be improved through:
Prompt Optimization - Refining instructions for field extraction
Domain Examples - Providing sample extractions from your specific context
Field Definitions - Clarifying expectations and allowed values for each field
Validation Rules - Adding checks for required fields and format consistency
Model Selection - Choosing models that perform best for your field types
Getting Started
To evaluate extraction quality in your own context:
- Create reference extractions for sample text from your use case
- Define which fields are exact vs. semantic
- Test extraction with different models and compare accuracy
- Identify problematic field types requiring improvement
- Establish acceptable quality thresholds for deployment
- Monitor extraction quality on ongoing production data
For technical implementation details and evaluation tools, visit the GAIK GitHub repository.