Semantic Video Search
Natural language search across indexed video content with direct jump-to-moment navigation and multilingual retrieval.
Semantic Video Search Generic Use Case (Cross-Cutting Use Case)
This use case shows how the GAIK toolkit enables natural language search across a library of recorded video content — letting users describe what they are looking for in plain language and jump directly to the relevant moment in the video, rather than scrubbing through recordings manually.
Business layer – use case specification
At the business layer, the use case targets organisations that accumulate recorded videos — lectures, webinars, training sessions, procedure demonstrations — and struggle to make that knowledge accessible for search and reuse. Video content is difficult to search because knowledge is locked inside spoken words rather than indexed text. Users cannot find specific moments, topics are duplicated across recordings, and cross-language access is especially difficult. The solution indexes video transcripts as searchable segments and enables semantic, keyword, and hybrid search with precise timestamp retrieval.
Concrete example fragments reflected in the use case design include:
- A growing library of recorded videos covering specialised topics that users need to find efficiently
- Users want to search by concept or question, not by keyword alone, and jump directly to the relevant moment
- Videos are recorded in one language but users may search in another language
- Existing subtitle files or transcription output can be ingested without re-processing the video
- Success is defined as faster discovery of relevant content, reduced duplication of effort, and access to video knowledge as easily as document knowledge
The canvas clarifies the purpose of the solution, the main users (educators, students, content managers, researchers, and platform administrators), and the expected outcomes.
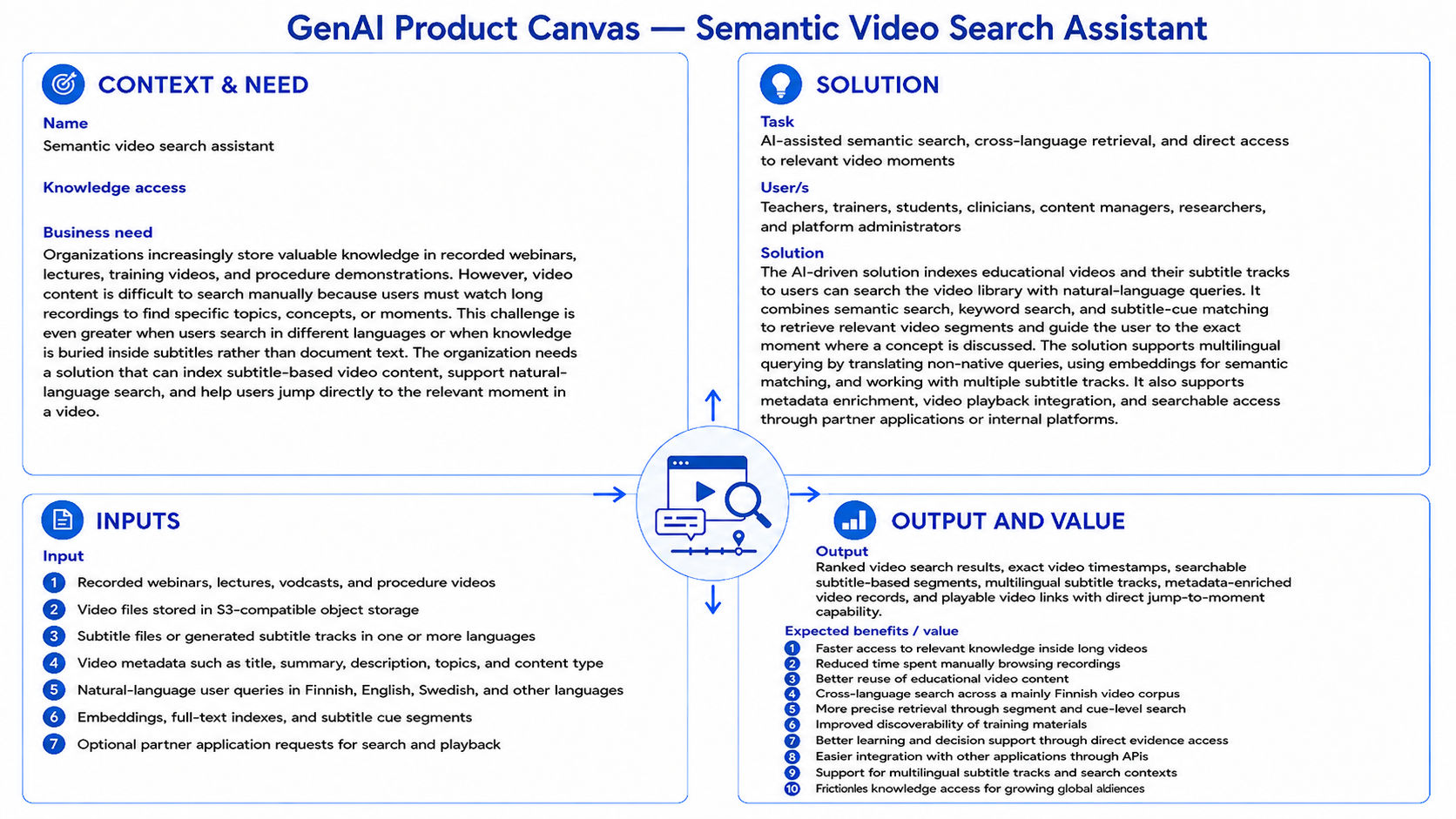
- Reference GenAI Product Canvas for Semantic Video Search — Download (video-search-canvas.png)
Strategy layer – value evaluation and monitoring
At the strategy layer, the value evaluation model applies the Value Evaluation Framework to this generic use case and makes value assumptions explicit.
Example value fragments from the model include:
Functional value (primary): "Faster semantic video search", "Direct jump to relevant moments in videos", "Cross-language search across subtitle tracks", "More precise segment and cue-level search", "Metadata and enriched video discovery", "Easy integration with partner applications and APIs", "Support for editable subtitle tracks and playback" → Outcome: Knowledge accessed faster and with higher quality
Informational value: "Faster discovery of relevant video moments", "Better visibility into subtitle-based knowledge", "Searchable and reusable video content", "Stronger multilingual knowledge access" → Outcome: Better knowledge access with trusted evidence
Financial value: "Low time-cost of finding relevant content", "Better reuse of existing video content", "Faster localization value from existing videos", "Reduced duplication of content-search effort" → Outcome: Lower access cost and better return on knowledge assets
Emotional value: "Higher confidence in search results", "Reduced frustration from browsing videos", "Less stress for learners, trainers, and content teams" → Outcome: Happier users and smoother knowledge access
Social value: "Better collaboration and wider audience access", "More inclusive learning experiences", "Stronger integration and broader educational reach" → Outcome: Stronger collaboration and broader educational reach
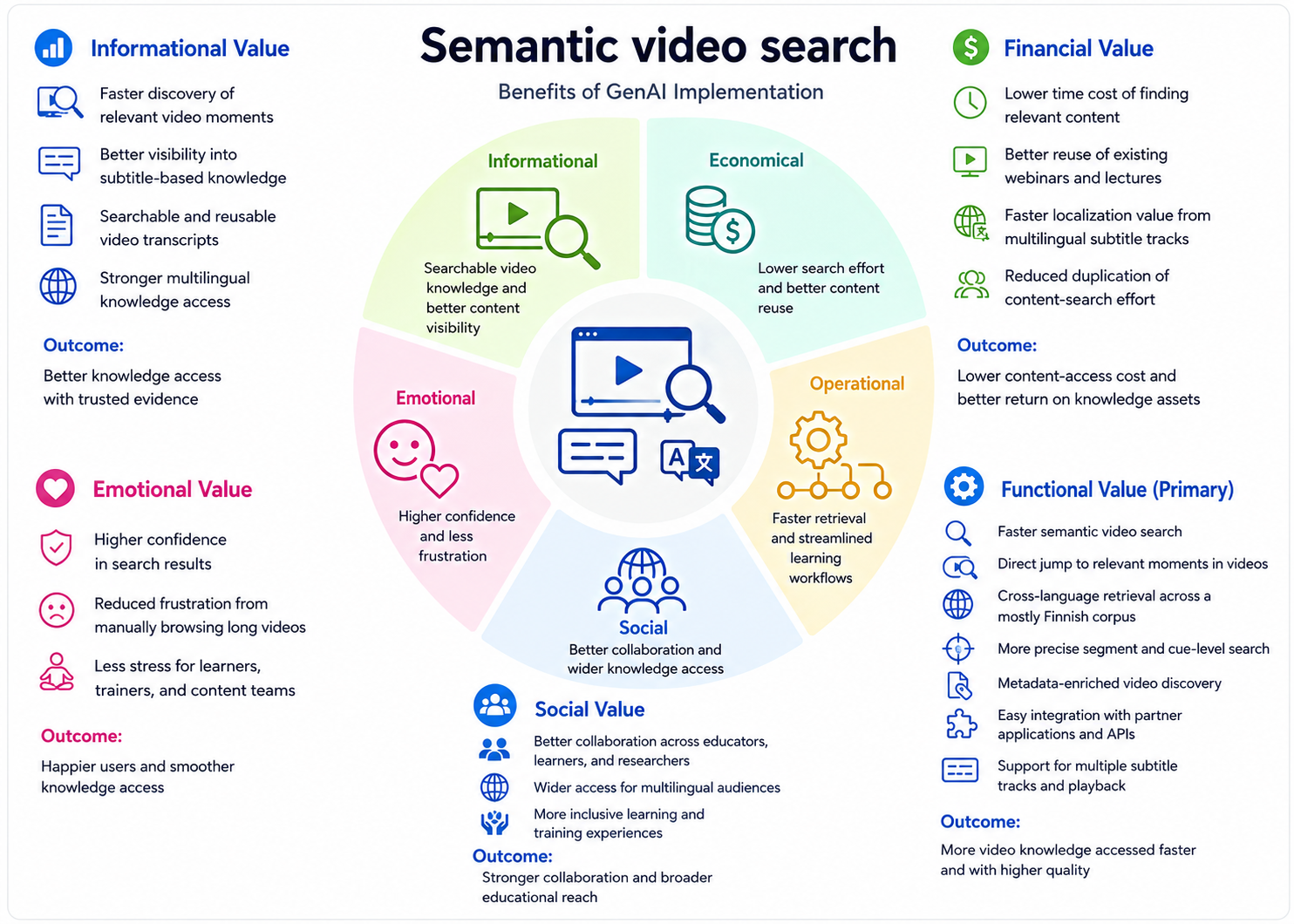
- Reference Value Evaluation Model for Semantic Video Search — Download (video-search-value.png)
The same model can be used both before implementation (to evaluate expected value) and after deployment (to monitor realized value across different dimensions).
Implementation Layer
The code-based implementation uses GAIK's Embedder and PgVectorStore components to build a searchable index of video segments. The SRT transcript segments used as index input typically come from the Transcription, Captioning & Translation pipeline — the Transcriber and TranscriptEnhancer components produce the timestamped text that feeds the indexing phase. The pipeline itself has two phases: an offline indexing phase that stores transcript segments as vectors, and an online search phase that retrieves the most relevant segments for playback navigation.
Software Components
1. Embedder
Generates dense vector representations of text using an embedding model. In the semantic video search pipeline, the Embedder is used in both phases: during indexing it transforms each transcript segment into a vector for storage, and during search it embeds the user's natural language query so it can be compared against stored segment vectors. Supports batched embedding for efficient ingestion of large transcript libraries.
📁
implementation_layer/src/gaik/software_components/RAG/embedder/
2. PgVectorStore
A PostgreSQL-backed vector store with HNSW indexing for fast similarity search. For the semantic video search use case it stores each transcript segment together with its video metadata — title, video ID, start time, and end time — enabling results to be returned not just as text but as navigable timestamps. Supports three search modes: semantic (pure vector similarity), keyword (full-text via tsvector), and hybrid (Reciprocal Rank Fusion combining both). An optional Finnish text processor can be plugged in to improve search quality for morphologically complex languages.
Cross-language search is supported through query translation: when a user queries in a language different from the indexed content, the query is automatically translated before embedding. Both the original query embedding and the translated query embedding are used in the semantic search, and their rankings are fused via RRF — enabling users to find content regardless of the language they search in.
Multi-language indexing allows the same video to be indexed in multiple languages simultaneously (e.g. Finnish and Swedish subtitles stored as separate segment sets). Each language is independently indexed so searches can be scoped to a specific language or run across all indexed languages.
Video-specific helper functions (ingest_video_segments, format_search_results) handle the segment ingestion and result formatting workflows, wrapping the store's general-purpose API in a video-oriented interface.
📁
implementation_layer/src/gaik/software_components/RAG/pg_vector_store/📁
implementation_layer/examples/software_components/RAG/video_search_example.py
3. Retriever (optional)
Provides a unified search interface over the vector store with optional cross-encoder re-ranking. In the semantic video search context, the Retriever can be added on top of the PgVectorStore search results to re-rank segments by relevance using a sentence-transformer cross-encoder model — useful when the query is ambiguous or the video library is large. The Retriever also supports threshold filtering to suppress low-confidence results.
📁
implementation_layer/src/gaik/software_components/RAG/retriever/
Downstream tasks
Once video segments are indexed, two downstream steps further enrich the system outside the GAIK RAG pipeline.
AI-generated video metadata is produced automatically after a video is indexed. An LLM analyses the transcript and generates a title, summary, description, list of topics, and content type classification for each video. This metadata is stored alongside the video record and makes the library more discoverable — users can browse by topic or content type in addition to searching by query. The metadata can be generated on demand or triggered automatically on ingestion.
Video playback integration is the final downstream step: search results are returned with precise start and end timestamps, allowing the application to jump the video player directly to the relevant moment. Subtitle tracks (in one or more languages) can also be attached to the player, enabling in-video caption display during playback.
Example output from the demo — natural language search across indexed video content with timestamp-based results and direct playback navigation:

To test the semantic video search use case, please visit the GAIK demo link. Access is available upon registration request.
Adaptable to Other Domains
The same indexing and retrieval pipeline applies to any domain where knowledge is locked in recorded video or audio — only the transcript source and optional language-specific text processing change:
- Corporate training video libraries, medical procedure recordings, legal hearing archives, e-learning course content, customer support video documentation
Evaluation Methods
Coming Soon: Evaluation methods for the semantic video search use case are under development.
Related Resources
Transcription, Captioning & Translation
AI-powered transcription, subtitle generation, transcript enhancement, and multilingual translation for educational and professional video content.
Construction Site Diary Creation
Automated daily site documentation from voice recordings and field observations into structured, standardized construction diaries.